ICLR 2026 Acceptance Prediction: Benchmarking Decision Process with A Multi-Agent System
A multi-agent system and benchmark for end-to-end peer review modeling, enabling real-world evaluation and predictive insights for future conference decisions.
🔮 ICLR 2026 Prediction Lookup
Enter your OpenReview submission ID or paper title to check predictions from our multi-agent system.
Want the complete dataset? Download all ~13,000 predictions with detailed reasoning.
📥 Download Full Accept List & ReasoningWhy and How We Build PaperDecision
Peer review is fundamental to academic research but remains challenging to model due to its subjectivity, dynamics, and multi-stage complexity. Previous efforts leveraging large language models (LLMs) have primarily explored isolated sub-tasks, such as review generation or score prediction, failing to capture the entire evaluation workflow.
To this end, we introduce PaperDecision to model the peer review process end-to-end. Central to our approach is PaperDecision-Bench, a large-scale multimodal benchmark that links OpenReview papers, reviews, rebuttals, and final decisions across multiple conference cycles. By continuously incorporating newly released conference rounds, the benchmark remains forward-looking and helps avoid risks of data leakage in evaluation.
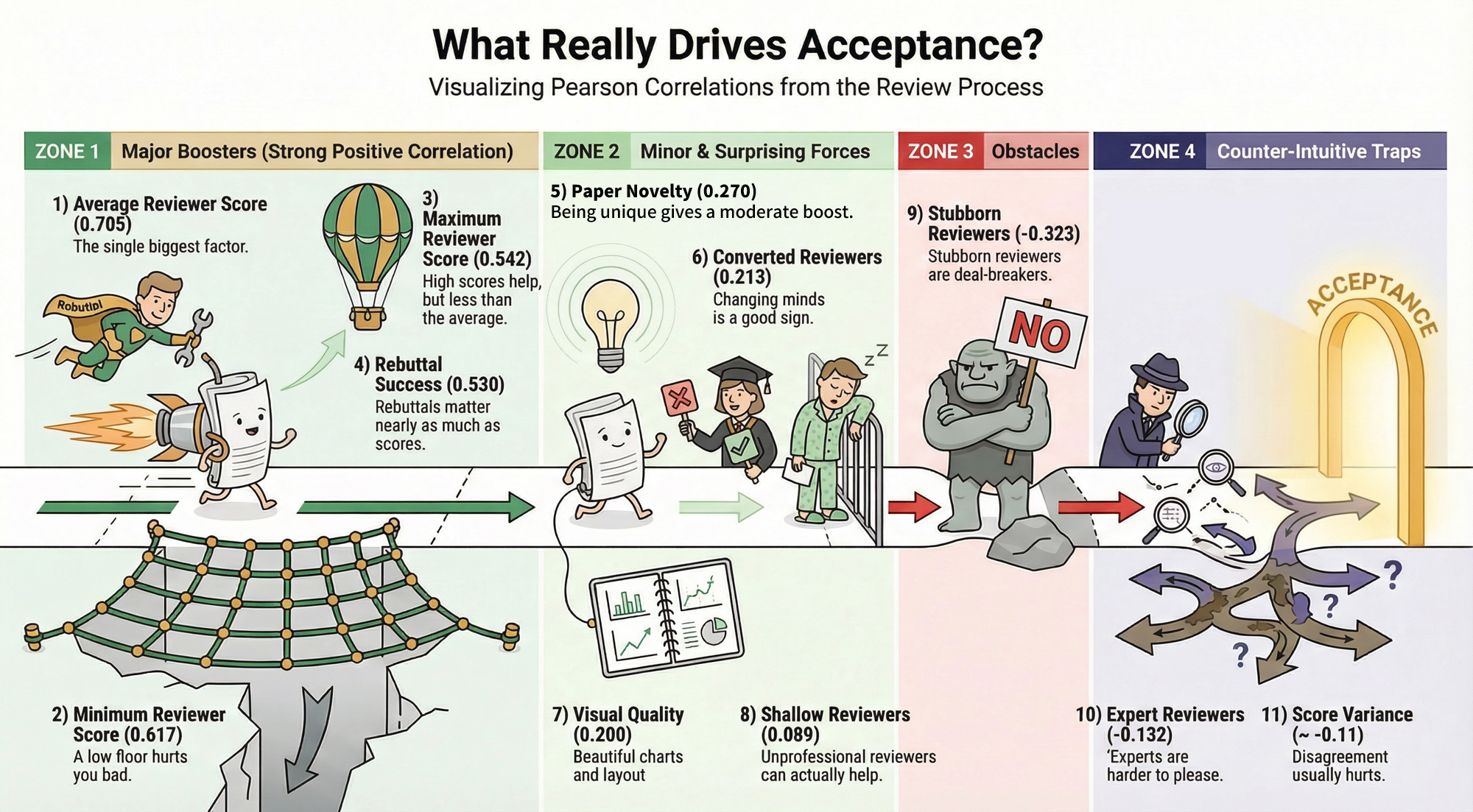
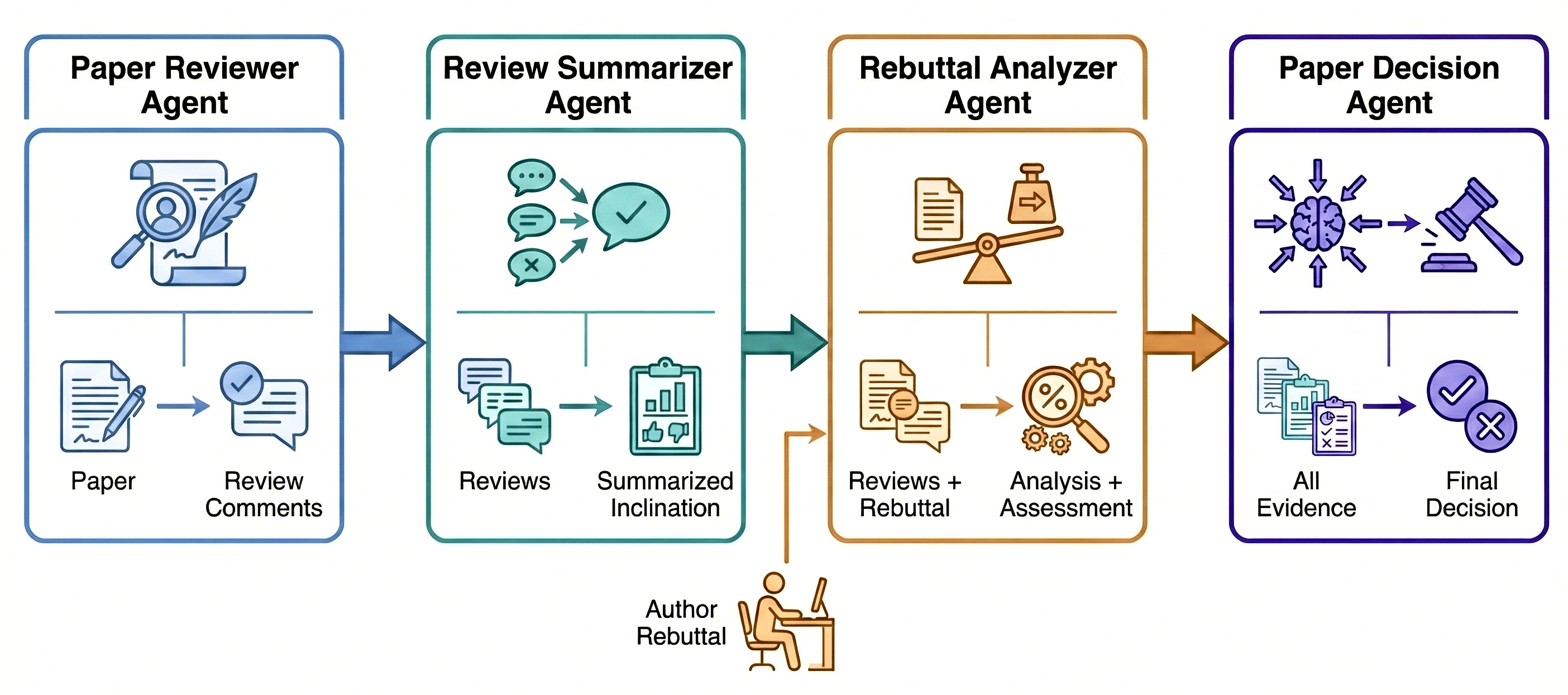
Building on this benchmark, we develop PaperDecision-Agent, a multi-agent system that simulates the roles and interactions of authors, reviewers, and area chairs. Empirically, frontier multimodal LLMs achieve up to ~82% accuracy in accept-reject prediction. We further provide in-depth analysis of the decision-making process, identifying several key factors associated with acceptance outcomes, such as reviewer expertise and score change. Overall, PaperDecision establishes the first dynamic and extensible benchmark for automated peer review, laying the groundwork for more accurate, transparent, and scalable AI-assisted paper decision systems.